

以下の内容は Anthropic 公式サイトの技術記事を転載し、AI によって翻訳されたものです。原文の全文は、こちらのリンクからご覧いただけます:https://www.anthropic.com/engineering/contextual-retrieval
AI モデルが特定のコンテキストで有用であるためには、背景知識へのアクセスが必要になることがよくあります。例えば、カスタマーサポートのチャットボットにはそのビジネス特有の知識が必要ですし、法律分析ボットには膨大な過去の判例の知識が必要です。
開発者は通常、検索拡張生成(RAG)を使用して AI モデルの知識を強化します。RAG は、ナレッジベースから関連情報を取得し、それをユーザーのプロンプトに追加することで、モデルの回答を大幅に向上させる手法です。問題は、従来の RAG ソリューションが情報をエンコードする際にコンテキストを削除してしまうため、システムがナレッジベースから関連情報を取得できなくなることがよくある点です。
本記事では、RAG における検索ステップを劇的に改善する方法を紹介します。この手法は「Contextual Retrieval(コンテキスト検索)」と呼ばれ、「Contextual Embeddings」と「Contextual BM25」という 2 つのサブテクニックを使用します。この手法により、検索の失敗を 49% 削減でき、リランキング(reranking)と組み合わせることで 67% 削減することができます。これらは検索精度の大きな改善を意味し、下流のタスクにおけるパフォーマンス向上に直結します。
Claude を使用した独自の Contextual Retrieval ソリューションは、こちらのクックブックで簡単にデプロイできます。
単に長いプロンプトを使用することについての注意点#
時には最もシンプルな解決策が最善であることもあります。ナレッジベースが 200,000 トークン(約 500 ページの資料)未満の場合は、RAG や同様の手法を必要とせず、ナレッジベース全体をモデルに渡すプロンプトに含めるだけで済みます。
数週間前、私たちは Claude 向けに プロンプト・キャッシュ(prompt caching) をリリースしました。これにより、このアプローチが大幅に高速化され、コスト効率も向上しました。開発者は API 呼び出しの間で頻繁に使用されるプロンプトをキャッシュできるようになり、遅延を 2 倍以上短縮し、コストを最大 90% 削減できます(動作については プロンプト・キャッシュ・クックブック をご覧ください)。
ただし、ナレッジベースが成長するにつれて、よりスケーラブルなソリューションが必要になります。そこで Contextual Retrieval の出番です。
RAG 入門:より大規模なナレッジベースへのスケーリング#
コンテキストウィンドウに収まらない大規模なナレッジベースの場合、RAG が標準的なソリューションとなります。RAG は以下の手順でナレッジベースを前処理します:
- ナレッジベース(文書の「コーパス」)を、通常数百トークン以下の小さなテキストチャンク(チャンク)に分解する。
- エンベディングモデルを使用して、これらのチャンクを意味をコード化したベクトルエンベディングに変換する。
- これらのエンベディングを、セマンティックな類似性による検索が可能なベクトルデータベースに保存する。
実行時にユーザーがモデルにクエリを入力すると、ベクトルデータベースを使用して、クエリとのセマンティックな類似性に基づいた関連性の高いチャンクを見つけます。その後、最も関連性の高いチャンクが生成モデルに送信されるプロンプトに追加されます。
エンベディングモデルはセマンティックな関係を捉えることには優れていますが、重要な完全一致を見逃すことがあります。幸いなことに、このような状況で役立つ古いテクニックがあります。BM25(Best Matching 25)は、語彙マッチングを使用して正確な単語やフレーズの一致を見つけるランキング関数です。一意の識別子や専門用語を含むクエリに対して特に効果的です。
BM25 は TF-IDF(Term Frequency-Inverse Document Frequency)の概念に基づいています。TF-IDF は、単語が集まり(コレクション)の中の文書にとってどれほど重要かを測定します。BM25 は、文書の長さを考慮し、語の出現頻度に飽和関数を適用することでこれを改善し、一般的な単語が結果を独占するのを防ぎます。
セマンティックエンベディングが失敗するケースで BM25 が成功する例を挙げます:ユーザーがテクニカルサポートのデータベースで「エラーコード TS-999」を検索したとします。エンベディングモデルは一般的なエラーコードに関するコンテンツを見つけるかもしれませんが、正確な「TS-999」の一致を見逃す可能性があります。BM25 はこの特定のテキスト文字列を探して、関連するドキュメントを特定します。
RAG ソリューションは、以下の手順でエンベディングと BM25 のテクニックを組み合わせることで、最も適用可能なチャンクをより正確に取得できます:
- ナレッジベース(ドキュメントの「コーパス」)を小さなテキストチャンクに分解する。
- これらのチャンクに対して TF-IDF エンコーディングとセマンティックエンベディングを作成する。
- BM25 を使用して、完全一致に基づいたトップチャンクを見つける。
- エンベディングを使用して、セマンティックな類似性に基づいたトップチャンクを見つける。
- ランクフュージョン(rank fusion)の手法を用いて、(3) と (4) の結果を組み合わせて重複を除去する。
- 上位 K 個のチャンクをプロンプトに追加して回答を生成する。
BM25 とエンベディングモデルの両方を活用することで、従来の RAG システムは、正確な用語マッチングと広範なセマンティックな理解を両立させ、より包括的かつ正確な結果を提供できます。
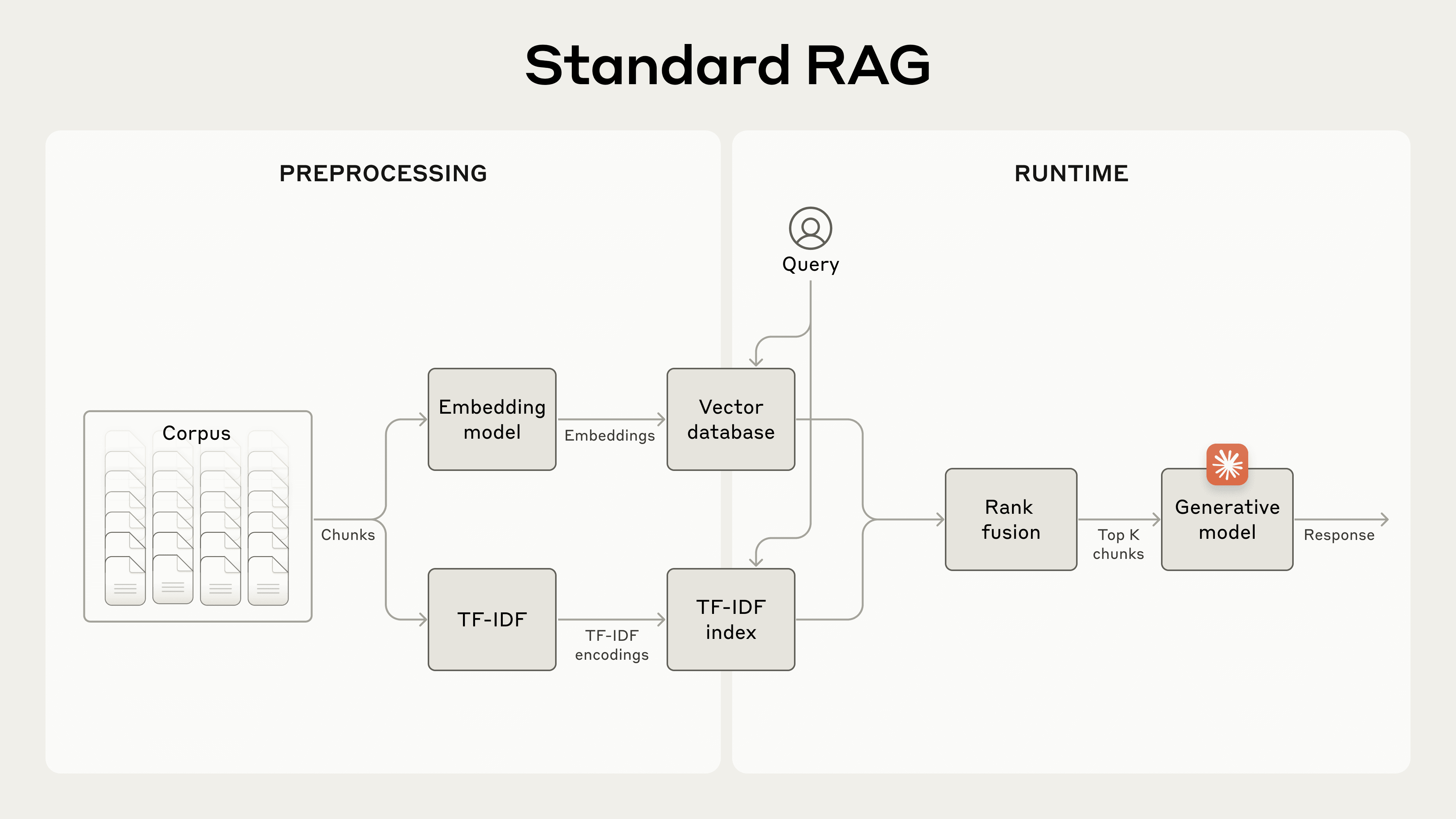
エンベディングと BM25 の両方を使用して情報を取得する標準的な RAG システム。
このアプローチにより、単一のプロンプトに収まる範囲をはるかに超えた膨大なナレッジベースに対しても、コスト効率よくスケーリングできます。しかし、これらの従来の RAG システムには大きな技術的限界があります。それは、コンテキスト(文脈)を破壊してしまうことがよくある点です。
従来の RAG におけるコンテキストの課題#
従来の RAG では、効率的な検索のためにドキュメントは通常小さなチャンクに分割されます。このアプローチは多くのアプリケーションで機能しますが、個々のチャンクに十分なコンテキストが欠けている場合に問題が生じる可能性があります。
例えば、ナレッジベースに財務情報(米国 SEC 提出書類など)が含まれており、次のような質問を受けた場合を想像してください:「ACME Corp の 2023 年第 2 四半期の売上成長率は?」
関連するチャンクには次のようなテキストが含まれているかもしれません:「同社の売上は前四半期比で 3% 増加しました。」 しかし、このチャンク単体ではどの会社を指しているのか、どの期間のことなのかが特定されておらず、正しい情報を取得したり、情報を効果的に使用したりすることが困難になります。
Contextual Retrieval(コンテキスト検索)の導入#
Contextual Retrieval は、エンベディング(「Contextual Embeddings」)および BM25 インデックス作成(「Contextual BM25」)の前に、各チャンクにチャンク固有の説明的なコンテキストを付加することで、この問題を解決します。
SEC 提出書類の例に戻りましょう。チャンクがどのように変換されるかの例を以下に示します:
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."検索を改善するためにコンテキストを使用するアプローチは過去にも提案されています。それらには、チャンクに一般的なドキュメントの要約を追加する(実験では効果が限定的)、仮想ドキュメントエンベディング(Hypothetical Document Embedding)、要約ベースのインデックス作成などが含まれます。これらの手法は、本記事で提案されているものとは異なります。
Contextual Retrieval の実装#
もちろん、ナレッジベース内の数万、数百万のチャンクに手動でアノテーションを付けるのは大変な作業です。Contextual Retrieval を実装するために、私たちは Claude を活用します。モデルに対し、ドキュメント全体のコンテキストを使用してチャンクを説明する、簡潔でチャンク固有のコンテキストを提供するよう指示するプロンプトを作成しました。各チャンクのコンテキスト生成には、以下の Claude 3 Haiku プロンプトを使用しました:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.生成されるコンテキストテキストは通常 50〜100 トークンで、エンベディング作成や BM25 インデックス作成の前にチャンクの冒頭に付加されます。
前処理の流れは以下のようになります:
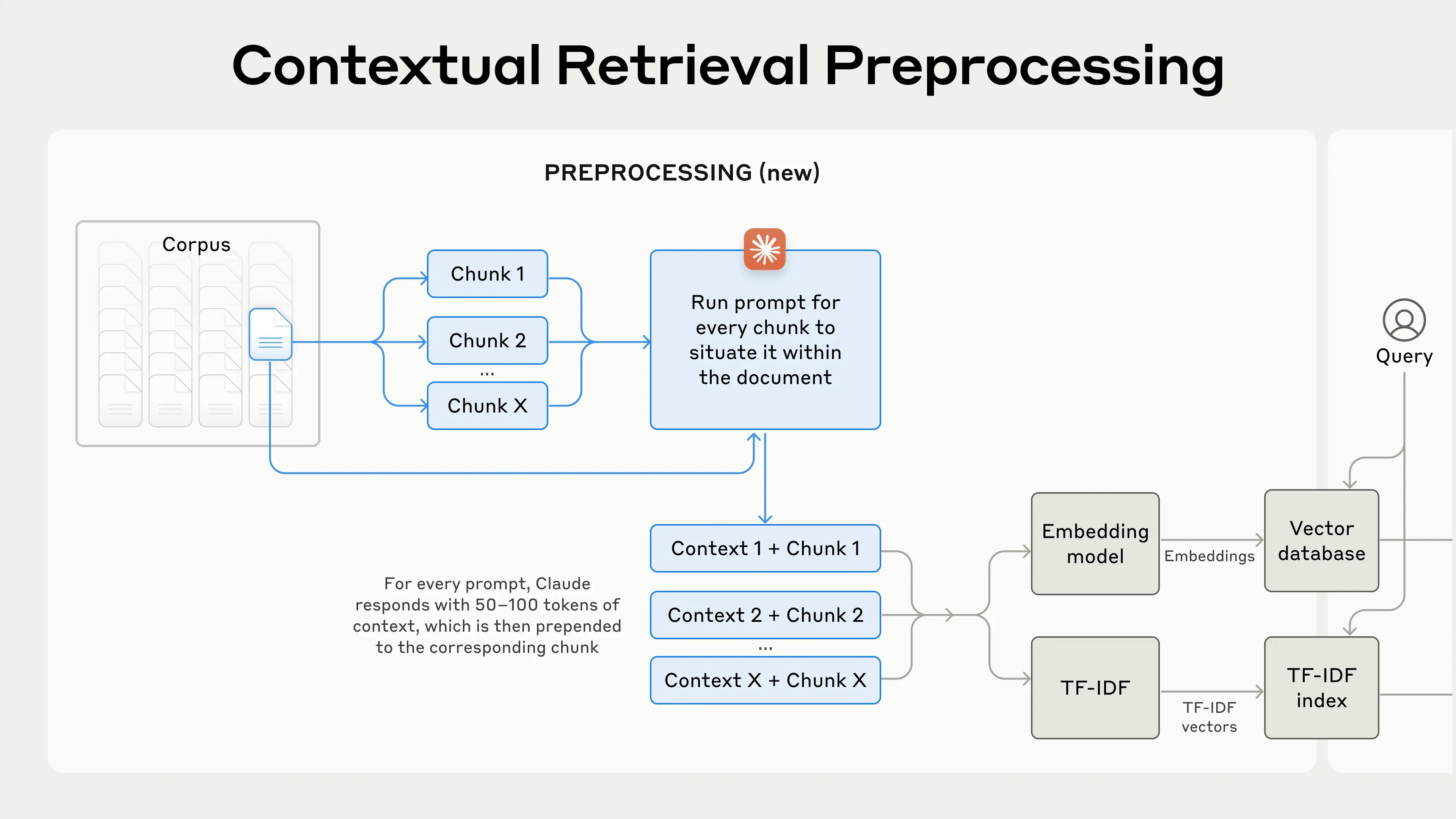
Contextual Retrieval は検索精度を向上させる前処理技術です。
Contextual Retrieval の導入に興味がある方は、こちらのクックブック から始めていただけます。
プロンプト・キャッシュによるコスト削減#
Contextual Retrieval は、冒頭に述べた Claude 特有のプロンプト・キャッシュ機能により、低コストで実現可能です。プロンプト・キャッシュにより、チャンクごとに参照ドキュメントを渡す必要はありません。ドキュメントを一度キャッシュに読み込み、その後は以前にキャッシュされたコンテンツを参照するだけです。チャンクを 800 トークン、ドキュメントを 8,000 トークン、コンテキスト指示を 50 トークン、各チャンクのコンテキストを 100 トークンと想定すると、コンテキスト化されたチャンクを作成するためのワンタイムコストは、100 万ドキュメントトークンあたりわずか 1.02 ドル です。